引言:当 AI 从实验室走向生产
读完这篇关于 Yelp Assistant 架构演进的深度文章,我感受到一种前所未有的务实。文章重点关注从基础的检索增强生成(RAG)原型到稳健生产环境的转变,详细介绍了四个关键的数据策略转变。
这不是简单的技术升级,而是 AI 落地的实战智慧。从原型到生产,中间隔着无数的坑和挑战,Yelp 的经验为我们提供了宝贵的参考。
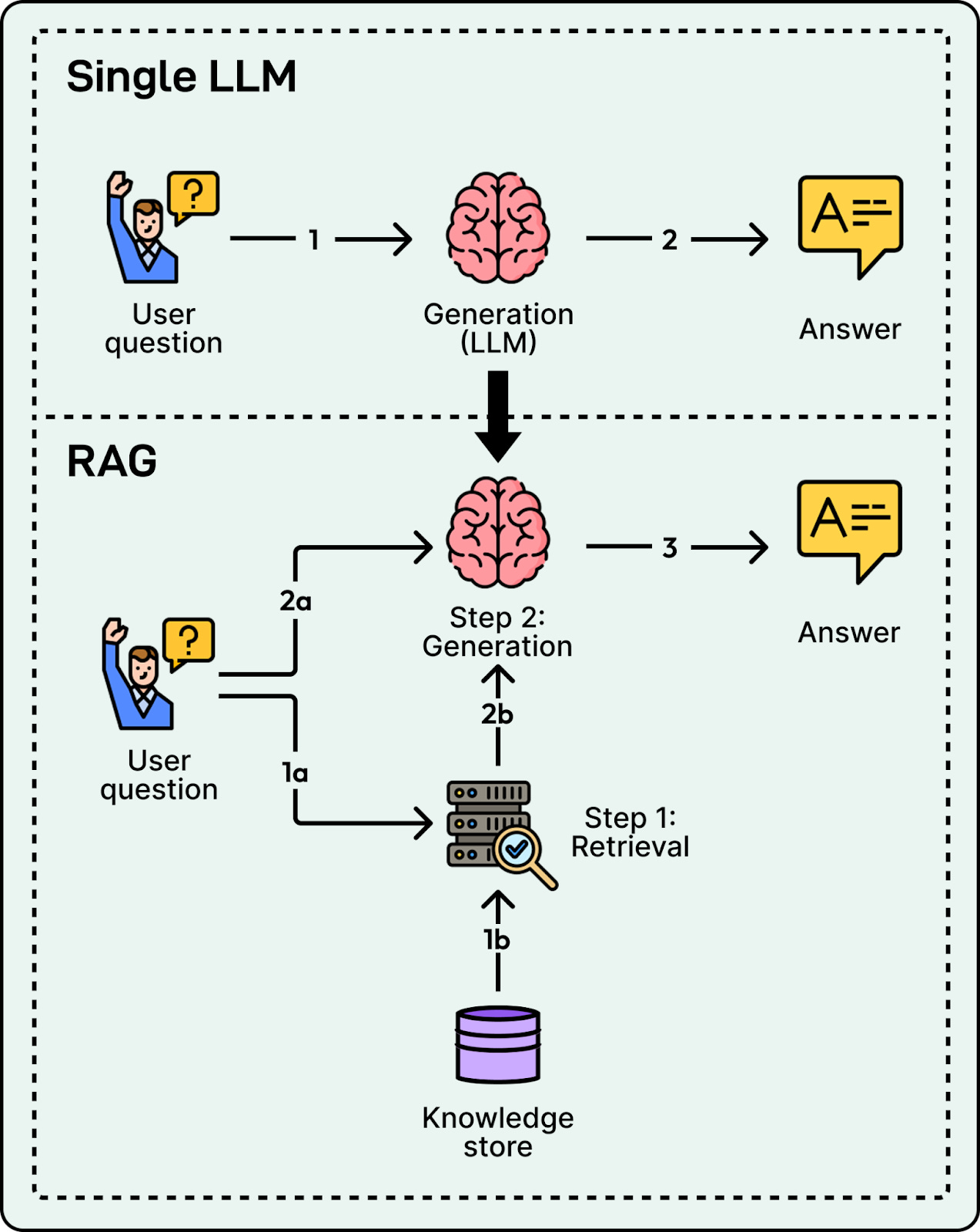
从 RAG 原型到生产环境:跨越鸿沟
文章首先探讨了从 RAG 原型到生产环境的转变。这让我思考一个问题:为什么从原型到生产这么难?
RAG 原型的特点:
- 数据量小:使用少量数据进行验证
- 功能简单:实现基本的检索和生成功能
- 性能要求低:对延迟和吞吐量要求不高
- 容错率高:可以接受一定的错误率
生产环境的要求:
- 数据量大:需要处理海量数据
- 功能复杂:需要支持各种复杂场景
- 性能要求高:对延迟和吞吐量要求很高
- 容错率低:几乎不能接受错误
这种转变的核心挑战在于:从”能用”到”好用”,从”验证想法”到”服务用户”,中间需要解决无数的技术和工程问题。
数据策略转变一:混合流式/批处理流水线
文章介绍的第一个数据策略转变是:通过混合流式/批处理流水线确保数据新鲜度。这个策略让我对数据管理有了新的认识。
流式流水线:
- 原理:实时处理数据,确保数据实时更新
- 优势:数据新鲜度高,延迟低
- 挑战:实现复杂,资源消耗大
批处理流水线:
- 原理:批量处理数据,定期更新
- 优势:实现简单,资源消耗小
- 挑战:数据新鲜度低,延迟高
混合流水线:
- 原理:结合流式和批处理的优势
- 优势:兼顾数据新鲜度和资源效率
- 挑战:实现复杂,需要精心设计
这个策略的意义在于:在数据新鲜度和资源效率之间找到平衡,确保 AI 助手能够提供最新、最准确的信息。
数据策略转变二:结构化事实与非结构化评论分离
文章介绍的第二个数据策略转变是:将结构化事实与非结构化评论分离。这个策略让我对数据架构有了新的认识。
结构化事实:
- 内容:商家信息、营业时间、地址等
- 特点:格式统一,易于查询
- 处理方式:使用数据库存储,通过 SQL 查询
非结构化评论:
- 内容:用户评论、评分、反馈等
- 特点:格式多样,难以查询
- 处理方式:使用向量数据库,通过向量检索
这种分离的意义在于:针对不同类型的数据,使用不同的存储和检索方式,提升查询效率和准确性。
数据策略转变三:利用文本和嵌入实现混合图片检索
文章介绍的第三个数据策略转变是:利用文本和嵌入实现混合图片检索。这个策略让我对多模态检索有了新的认识。
文本检索:
- 原理:通过文本描述检索图片
- 优势:直观,易于使用
- 挑战:需要准确的文本描述
嵌入检索:
- 原理:通过图片的向量嵌入检索相似图片
- 优势:可以找到视觉上相似的图片
- 挑战:需要训练嵌入模型
混合检索:
- 原理:结合文本和嵌入检索的优势
- 优势:兼顾准确性和灵活性
- 挑战:需要设计合理的融合策略
这个策略的意义在于:通过多模态检索,提升用户体验,让用户可以通过多种方式找到想要的图片。
数据策略转变四:统一的内容获取 API
文章介绍的第四个数据策略转变是:通过统一的内容获取 API 实现集中访问。这个策略让我对 API 设计有了新的认识。
分散访问:
- 原理:每个数据源有独立的 API
- 优势:灵活性高
- 挑战:难以管理,难以保证一致性
统一 API:
- 原理:所有数据源通过统一的 API 访问
- 优势:易于管理,易于保证一致性
- 挑战:设计复杂,需要抽象
这个策略的意义在于:通过统一的 API,简化数据访问,提升系统的可维护性和可扩展性。
推理优化一:将单体 LLM 解构为专用模型
文章介绍的第一个推理优化是:将单体 LLM 解构为用于护栏和关键词生成的专用模型。这个优化让我对模型架构有了新的认识。
单体 LLM:
- 原理:一个模型处理所有任务
- 优势:简单,易于部署
- 挑战:效率低,难以优化
专用模型:
- 原理:多个模型各司其职,每个模型专注于特定任务
- 优势:效率高,易于优化
- 挑战:复杂,需要协调
这种解构的意义在于:通过专用化,提升每个任务的效率和质量,同时降低整体成本。
推理优化二:通过并行化和分层模型优化推理效率
文章介绍的第二个推理优化是:通过并行化和分层模型优化推理效率,将延迟从 10 秒降低到 3 秒以下。这个优化让我对推理优化有了新的认识。
并行化:
- 原理:同时执行多个任务,减少总时间
- 优势:大幅提升效率
- 挑战:需要设计合理的并行策略
分层模型:
- 原理:使用不同规模的模型处理不同复杂度的任务
- 优势:在保证质量的同时提升效率
- 挑战:需要设计合理的分层策略
这个优化的意义在于:从 10 秒降低到 3 秒以下,延迟降低 70% 以上,用户体验大幅提升。
评估框架:使用 LLM-as-a-judge 的多维度评估
文章介绍的评估框架是:建立使用 LLM-as-a-judge 的多维度评估框架。这个框架让我对 AI 评估有了新的认识。
LLM-as-a-judge:
- 原理:使用 LLM 作为评估器,评估 AI 助手的回答质量
- 优势:可以评估多个维度,评估结果客观
- 挑战:需要设计合理的评估提示词
多维度评估:
- 准确性:回答是否准确
- 相关性:回答是否相关
- 完整性:回答是否完整
- 有用性:回答是否有用
这个评估框架的意义在于:通过多维度评估,全面了解 AI 助手的表现,为持续优化提供数据支持。
深度思考:AI 落地的核心是什么?
读完这篇文章,我一直在思考一个问题:AI 落地的核心是什么?
第一,不是模型。模型只是基础,不是核心。AI 落地的核心是数据和工程。
第二,不是算法。算法只是手段,不是核心。AI 落地的核心是系统架构和流程优化。
第三,不是技术。技术只是工具,不是核心。AI 落地的核心是用户体验和业务价值。
AI 落地的核心是:通过数据和工程的优化,将 AI 从原型转化为生产系统,为用户提供真正有价值的服务。
实践启示:如何实现 AI 落地?
作为从业者,我们需要思考如何实现 AI 落地。
第一,重视数据策略。通过混合流水线、数据分离、混合检索、统一 API 等策略,优化数据管理。
第二,优化推理效率。通过模型解构、并行化、分层模型等方法,优化推理效率。
第三,建立评估框架。通过 LLM-as-a-judge 的多维度评估框架,全面评估 AI 助手的表现。
第四,关注用户体验。通过降低延迟、提升准确性、增强相关性等方式,提升用户体验。
第五,持续迭代优化。通过数据分析和用户反馈,持续优化 AI 助手的性能。
这些方法不是一蹴而就的,需要长期投入和持续优化。但只有这样,才能实现真正的 AI 落地。
总结:从原型到生产,跨越鸿沟的智慧
这篇文章让我深刻认识到,从 RAG 原型到生产环境,中间隔着无数的坑和挑战。Yelp 的经验为我们提供了宝贵的参考。
作为从业者,我们需要:
- 理解从原型到生产的差距:认识到原型和生产环境的巨大差异
- 重视数据策略:通过混合流水线、数据分离、混合检索、统一 API 等策略,优化数据管理
- 优化推理效率:通过模型解构、并行化、分层模型等方法,优化推理效率
- 建立评估框架:通过 LLM-as-a-judge 的多维度评估框架,全面评估 AI 助手的表现
- 关注用户体验:通过降低延迟、提升准确性、增强相关性等方式,提升用户体验
AI 落地不是一蹴而就的,需要长期投入和持续优化。但只有这样,才能让 AI 真正为用户创造价值。