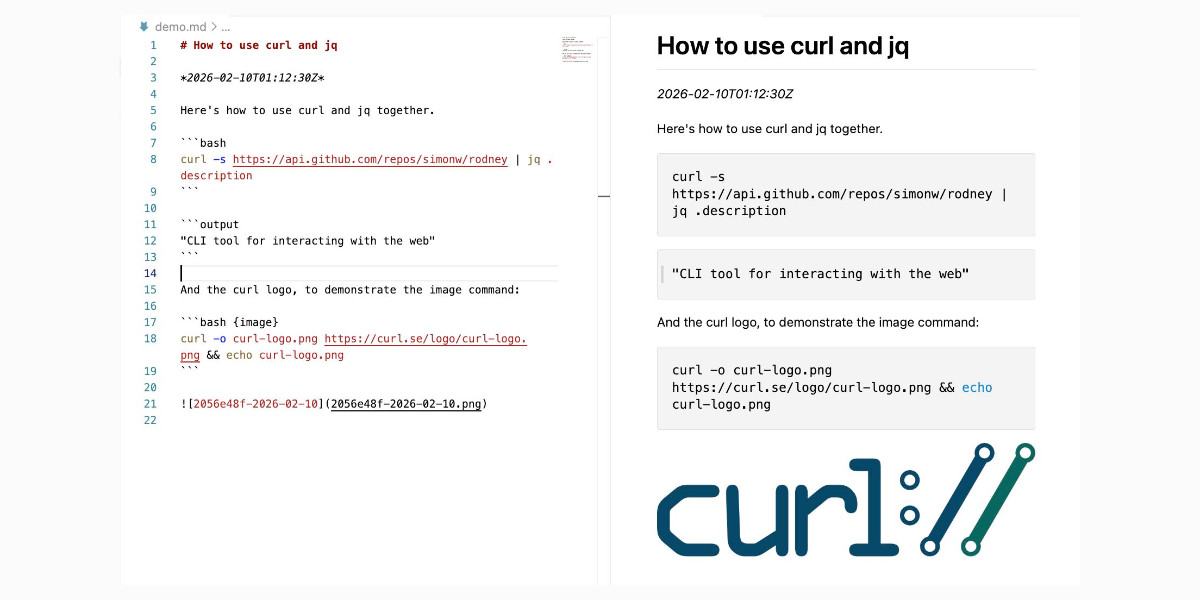
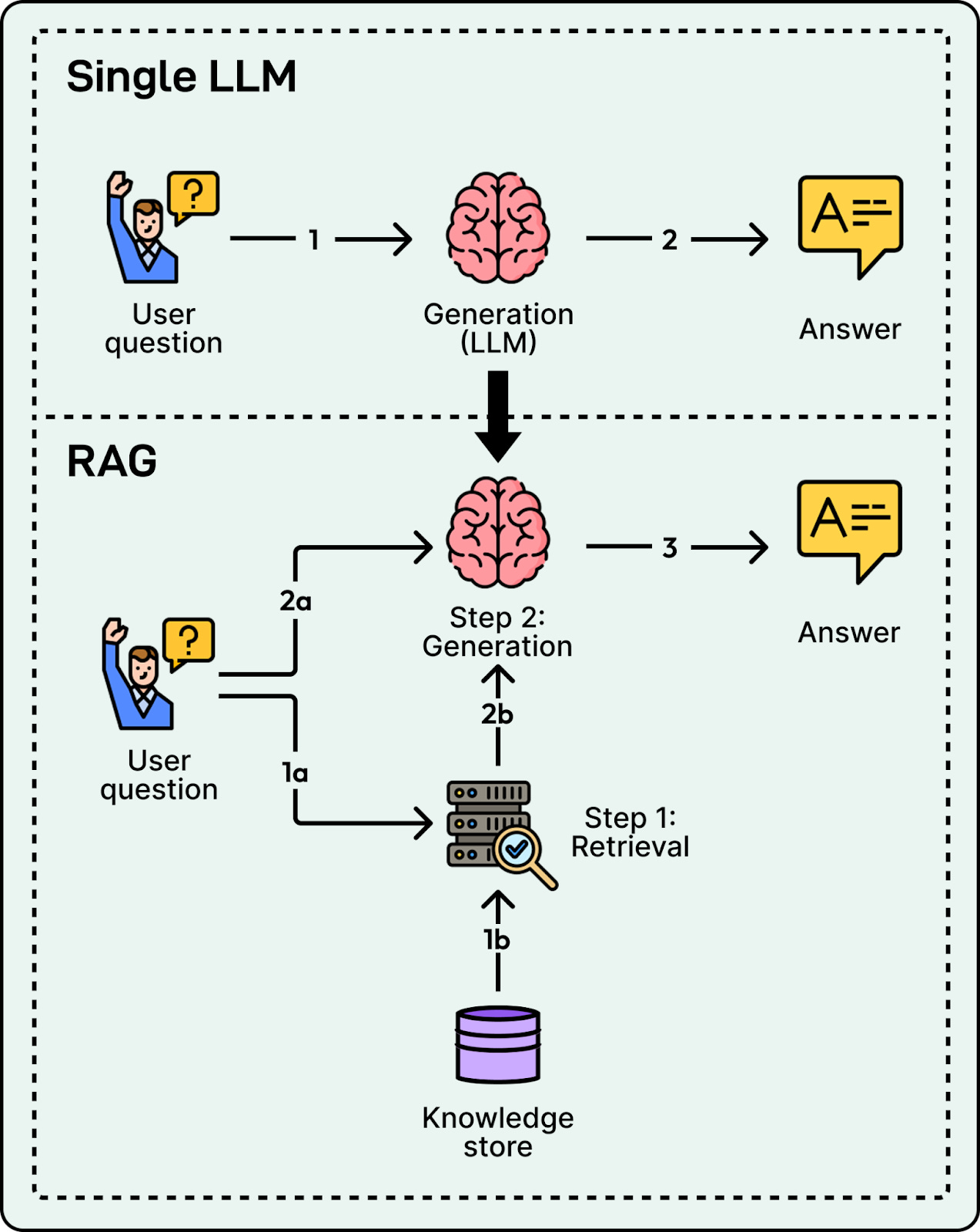
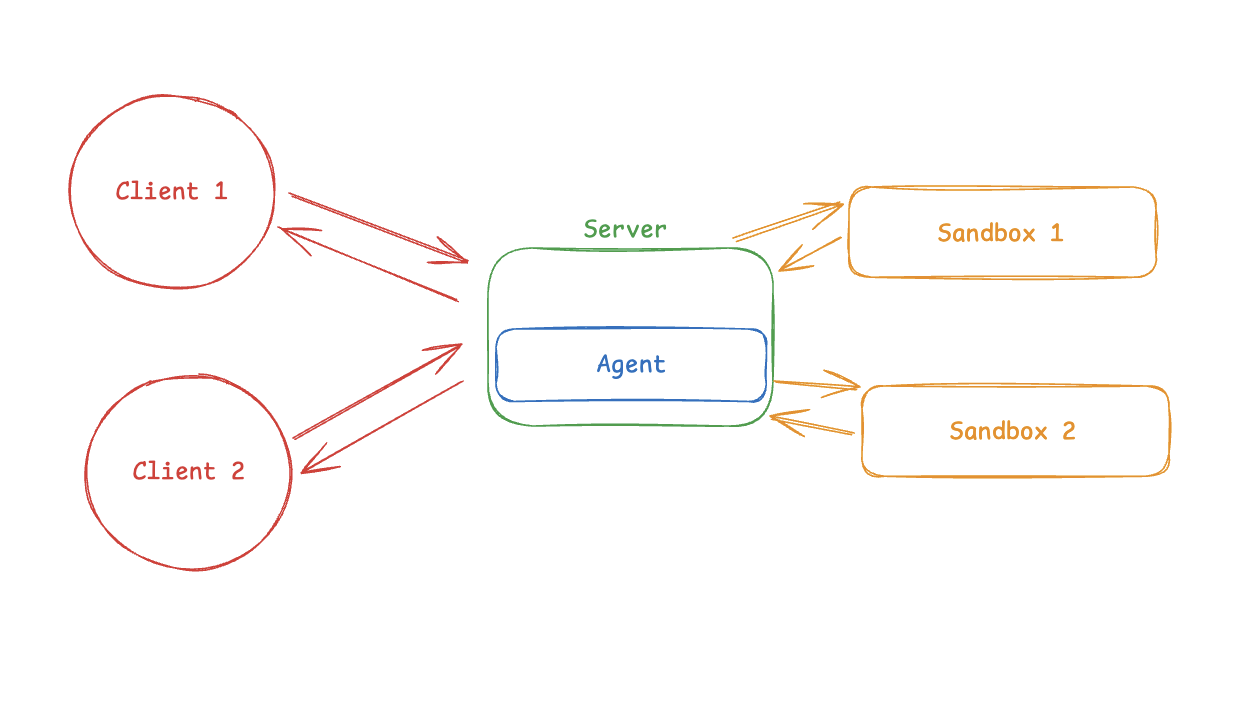
金句开头:当 AI 学习机从“辅助工具”变成“主要工具”时,真正的竞争不再是“谁的功能更强”,而是“谁能真正解决父母的焦虑”——那些真正有效的 AI 学习机,其实是在重新定义“家庭教育”这件事。
一、为什么“AI 学习机”这么重要?
因为焦虑决定需求。
当父母因为“不会辅导孩子”而焦虑时,他们需要的不是“更好的辅导方法”,而是“不需要辅导的方法”。
AI 学习机正好满足了这种需求:
旧方式:父母辅导孩子,父母焦虑,孩子也焦虑。
新方式:AI 学习机辅导孩子,父母不焦虑,孩子也不焦虑。
但这里有一个陷阱:AI 学习机真的能缓解父母的焦虑吗?
二、为什么大多数 AI 学习机“无效”?
不是技术问题,而是需求理解问题。
大多数 AI 学习机想的是:“我怎么用 AI 教孩子?”
但真正的问题应该是:“我怎么用 AI 缓解父母的焦虑?”
前者是“教育思维”——把 AI 当成一个“更好的老师”。
后者是“焦虑缓解思维”——把 AI 当成一个“焦虑缓解工具”。
三、AI 学习机真的能缓解父母的焦虑吗?
能,但前提是“设计对了”。
如果 AI 学习机只是“用 AI 教孩子”,那它不能缓解父母的焦虑,因为父母的焦虑不是“孩子学不会”,而是“我不知道孩子学得怎么样”。
如果 AI 学习机是“用 AI 告诉父母,孩子学得怎么样”,那它就能缓解父母的焦虑,因为父母的焦虑是“我不知道孩子学得怎么样”,而不是“孩子学不会”。
四、如何设计“真正有效”的 AI 学习机?
三个核心要素:
1. 不是“教孩子”,而是“告诉父母”
不是“用 AI 教孩子”,而是“用 AI 告诉父母,孩子学得怎么样”。
错误做法:AI 学习机只教孩子,不告诉父母。
正确做法:AI 学习机既教孩子,又告诉父母“孩子学得怎么样”。
2. 不是“功能越多越好”,而是“焦虑越少越好”
不是“我有很多功能”,而是“我能缓解父母的焦虑”。
错误做法:AI 学习机有很多功能,但父母不知道哪个功能有用。
正确做法:AI 学习机只有几个核心功能,但每个功能都能缓解父母的焦虑。
3. 不是“替代父母”,而是“赋能父母”
不是“AI 学习机替代父母”,而是“AI 学习机赋能父母”。
错误做法:AI 学习机完全替代父母,父母什么都不用管。
正确做法:AI 学习机帮助父母,让父母知道“该做什么,不该做什么”。
五、总结:AI 学习机的本质
不是技术问题,而是需求理解问题:当 AI 学习机从“辅助工具”变成“主要工具”时,真正的竞争是“谁能真正解决父母的焦虑”。
三个核心要素:告诉父母、缓解焦虑、赋能父母。
真正的挑战:不是“如何用 AI 教孩子”,而是“如何用 AI 缓解父母的焦虑”。
行动建议:如果你在开发 AI 学习机,不要只想着“怎么用 AI 教孩子”,而要想着“怎么用 AI 缓解父母的焦虑”。
金句结尾:当 AI 学习机从“辅助工具”变成“主要工具”时,真正的竞争不再是“谁的功能更强”,而是“谁能真正解决父母的焦虑”。那些真正有效的 AI 学习机,其实是在重新定义“家庭教育”这件事。所以,如果你想做好 AI 学习机,不是去学更多“AI 技巧”,而是去理解“父母的焦虑是什么,怎么用 AI 缓解这种焦虑”。
金句开头:当 AI 智能体从“辅助工具”变成“主要员工”时,真正的竞争不再是“谁有更多员工”,而是“谁有更好的系统”——那些用 AI 智能体组建“一人公司”的人,其实是在重新定义“公司”这件事。
一、为什么“AI 智能体一人公司”这么重要?
因为系统决定规模。
当你的公司还是“传统公司”时,你的规模受限于“员工数量”。
当你的公司变成“AI 智能体公司”时,你的规模受限于“系统设计”。
那些用 AI 智能体组建“一人公司”的人,其实是在重新定义“公司”这件事:
旧定义:公司 = 一群人一起工作
新定义:公司 = 一个人 + 一套系统 + 一群 AI 智能体
二、为什么大多数人“不相信”?
不是技术问题,而是思维局限问题。
大多数人想的是:“AI 智能体怎么可能替代员工?”
但真正的问题应该是:“AI 智能体怎么不能替代员工?”
前者是“替代思维”——把 AI 智能体当成“员工的替代品”。
后者是“系统思维”——把 AI 智能体当成“系统的组成部分”。
三、“AI 智能体一人公司”真的可能吗?
可能,但前提是“设计对了”。
如果 AI 智能体只是“替代员工”,那它不可能,因为 AI 智能体没有“创造力”。
如果 AI 智能体是“系统的组成部分”,那它可能,因为系统不需要“创造力”,只需要“执行能力”。
那些用 AI 智能体组建“一人公司”的人,其实是在做一件事:设计一个系统,让 AI 智能体自动执行。
四、如何设计“AI 智能体一人公司”?
三个核心要素:
1. 不是“替代员工”,而是“设计系统”
不是“我用 AI 智能体替代员工”,而是“我设计一个系统,让 AI 智能体自动执行”。
错误做法:试图用 AI 智能体替代所有员工,结果系统崩溃。
正确做法:设计一个系统,让 AI 智能体执行“重复性高、逻辑清晰”的任务,其他任务用传统方式做。
2. 不是“功能越多越好”,而是“系统越稳越好”
不是“我有很多 AI 智能体”,而是“我有一个稳定的系统”。
错误做法:试图用很多 AI 智能体做很多事,结果系统不稳定。
正确做法:用几个核心 AI 智能体做几件核心事,其他事用传统方式做。
3. 不是“完全自动化”,而是“半自动化”
不是“我完全不用管”,而是“我设计系统,让系统自动运行,我只需要监控和优化”。
错误做法:试图让 AI 智能体完全自动化,结果系统出问题没人管。
正确做法:让 AI 智能体半自动化,核心决策还是人来做,执行交给 AI 智能体。
五、总结:AI 智能体一人公司的本质
不是技术问题,而是系统设计问题:当 AI 智能体从“辅助工具”变成“主要员工”时,真正的竞争是“系统设计”。
三个核心要素:设计系统、系统稳定、半自动化。
真正的挑战:不是“如何用 AI 智能体替代员工”,而是“如何设计一个系统,让 AI 智能体自动执行”。
行动建议:如果你也想组建“AI 智能体一人公司”,不要想着“替代员工”,而要想着“设计系统”,让 AI 智能体成为系统的组成部分。
金句结尾:当 AI 智能体从“辅助工具”变成“主要员工”时,真正的竞争不再是“谁有更多员工”,而是“谁有更好的系统”。那些用 AI 智能体组建“一人公司”的人,其实是在重新定义“公司”这件事。所以,如果你想组建“AI 智能体一人公司”,不是去学更多“AI 技巧”,而是去学“如何设计系统,让 AI 智能体成为系统的组成部分”。